
The traditional calculus of infrastructure ownership has fundamentally shifted in the era of artificial intelligence development. According to AlterSquare analysis, operating a machine learning workload with four NVIDIA A100 GPUs over a three-year period in an on-premises configuration costs $246,624, while cloud alternatives deliver the same computational capacity for just $122,478, a savings approaching 50%. For strategies to maximize these savings, our GPU cost optimization playbook provides comprehensive techniques. This dramatic cost differential has transformed GPU infrastructure from an enterprise-exclusive asset into an accessible resource for small teams, individual researchers, and startups building the next generation of AI applications.
As organizations worldwide navigate the accelerating demands of AI development in 2025, understanding the economics, performance characteristics, and strategic implications of cloud GPU rentals versus on-premises ownership has become essential for making infrastructure decisions that balance performance, flexibility, and financial sustainability.
The Hidden Costs Behind On-Premises GPU Infrastructure
Purchasing graphics processing units represents merely the starting point in a comprehensive ownership cost structure that extends far beyond initial hardware acquisition. A thorough examination of total ownership costs reveals why even affordable GPU hardware purchased outright frequently proves more expensive than cloud alternatives over meaningful timeframes.
Capital Expenditure and Supporting Hardware
The sticker price of high-performance GPUs reflects only a fraction of true infrastructure costs. A single NVIDIA H100 GPU commands over $30,000 at retail pricing, while an eight-GPU server configuration easily exceeds $250,000 before considering essential supporting infrastructure. These figures represent the baseline for calculating total ownership costs.
Supporting hardware compounds expenses substantially. Enterprise-grade server chassis engineered to accommodate multiple high-power GPUs, high-end CPUs providing sufficient PCIe lanes for GPU communication, massive RAM allocations, high-speed networking equipment for cluster communication, and robust power delivery systems all add tens of thousands to base GPU costs.
Ongoing Operational Expenses
Power consumption represents a substantial recurring cost that persists throughout the ownership lifecycle. Eight H100 GPUs alone consume over 5.6 kilowatts, and incorporating CPUs, networking equipment, and cooling infrastructure pushes total power requirements beyond 10 kilowatts. Depending on regional electricity rates, this translates to $1,000 to $2,000 monthly exclusively for power consumption.
Cooling requirements multiply operational costs beyond simple power consumption. High-density GPU servers generate tremendous heat requiring sophisticated cooling solutions. Many organizations implement liquid cooling systems that improve thermal performance but demand significant upfront investment and ongoing maintenance.
Infrastructure and Personnel Requirements
Physical space requirements extend beyond simple server rack allocation. Proper GPU infrastructure necessitates climate-controlled environments, backup power systems for uptime during electrical disruptions, redundant networking to prevent communication bottlenecks, and frequently specialized facilities meeting specific environmental requirements.
Staffing costs for IT professionals managing hardware, performing updates, troubleshooting issues, and maintaining system health add another $500-$1,000 monthly minimum for organizations with existing IT teams. Organizations lacking internal expertise face substantially higher costs.
How Cloud Rentals Democratize Powerful GPU Access
Cloud GPU platforms have fundamentally reshaped access to high-performance computing by eliminating traditional barriers while frequently delivering superior economics compared to ownership models.
Immediate Access to Latest Hardware
Cloud providers continuously upgrade infrastructure, providing customers immediate access to newest GPU generations without migration costs or hardware disposal challenges. When NVIDIA releases new architectures like the H200 or B200, cloud users simply switch instance types rather than confronting equipment obsolescence and capital depreciation.
This continuous hardware refresh democratizes powerful GPU capabilities that would otherwise remain exclusive to well-funded organizations. Individual researchers can experiment with cutting-edge H100 or H200 GPUs for a few dollars per hour rather than investing hundreds of thousands in hardware.
Pay-As-You-Go Economics
Cloud billing aligns costs directly with utilization, eliminating waste from idle hardware. Organizations pay exclusively for active computation, avoiding sunk costs of owned equipment remaining dormant during development lulls or between projects.
This economic model proves particularly valuable for workloads exhibiting variable intensity. Training a model might require intensive GPU usage for days or weeks, followed by months of minimal computational needs. Cloud rentals scale costs with this operational reality rather than forcing continuous infrastructure expenses.
Eliminated Infrastructure Overhead
Cloud platforms handle all infrastructure complexity, power provisioning, thermal management, networking configuration, physical security, and hardware maintenance. Development teams focus entirely on applications rather than wrestling with operational concerns.
The value of this abstraction extends beyond direct cost savings. Engineering hours spent managing infrastructure represent opportunity cost, time better invested in model development, feature implementation, or product improvement.
Comprehensive Cost Comparison: Cloud Versus On-Premise
Examining the total cost of ownership across a three-year operational period reveals the substantial economic advantages cloud GPU rentals deliver for most use cases.
For an eight-GPU H100 configuration operated over three years, on-premises deployment incurs hardware acquisition costs of approximately $247,766, infrastructure expenses (facility upgrades, cooling systems, networking) totaling $42,624, and operating costs (power, cooling, maintenance, personnel) reaching $144,000. This produces a total three-year cost of $434,390.
Cloud rental of equivalent capacity, assuming moderate utilization patterns typical of AI development workflows. For an eight-GPU H100 configuration operated continuously over a three-year period, Spheron delivers the most cost-efficient model, with a total compute cost of $491,482 at an hourly rate of $2.34 per GPU.
By contrast, equivalent cloud GPU deployments from hyperscalers incur significantly higher expenses over the same duration:
- AWS, priced at $3.933/hr per GPU, totaling $826,346
- Microsoft Azure, priced at $6.98/hr per GPU, totaling $1,465,075
- Google Cloud, priced at $11.06/hr per GPU, totaling $2,322,758
This means Spheron reduces three-year infrastructure spending by:
- $334,864 vs AWS (≈ 41% cost reduction)
- $973,593 vs Azure (≈ 66% cost reduction)
- $1,831,276 vs GCP (≈ 79% cost reduction)
Spheron's pricing advantage enables AI teams to scale compute more aggressively while significantly reducing long-term cloud rental expenses, unlocking more experimentation, faster iteration cycles, and materially improved capital efficiency in AI development. For more details on pricing options, visit our pricing page. If you want a comparison with other providers, check out our top GPU rental guide.
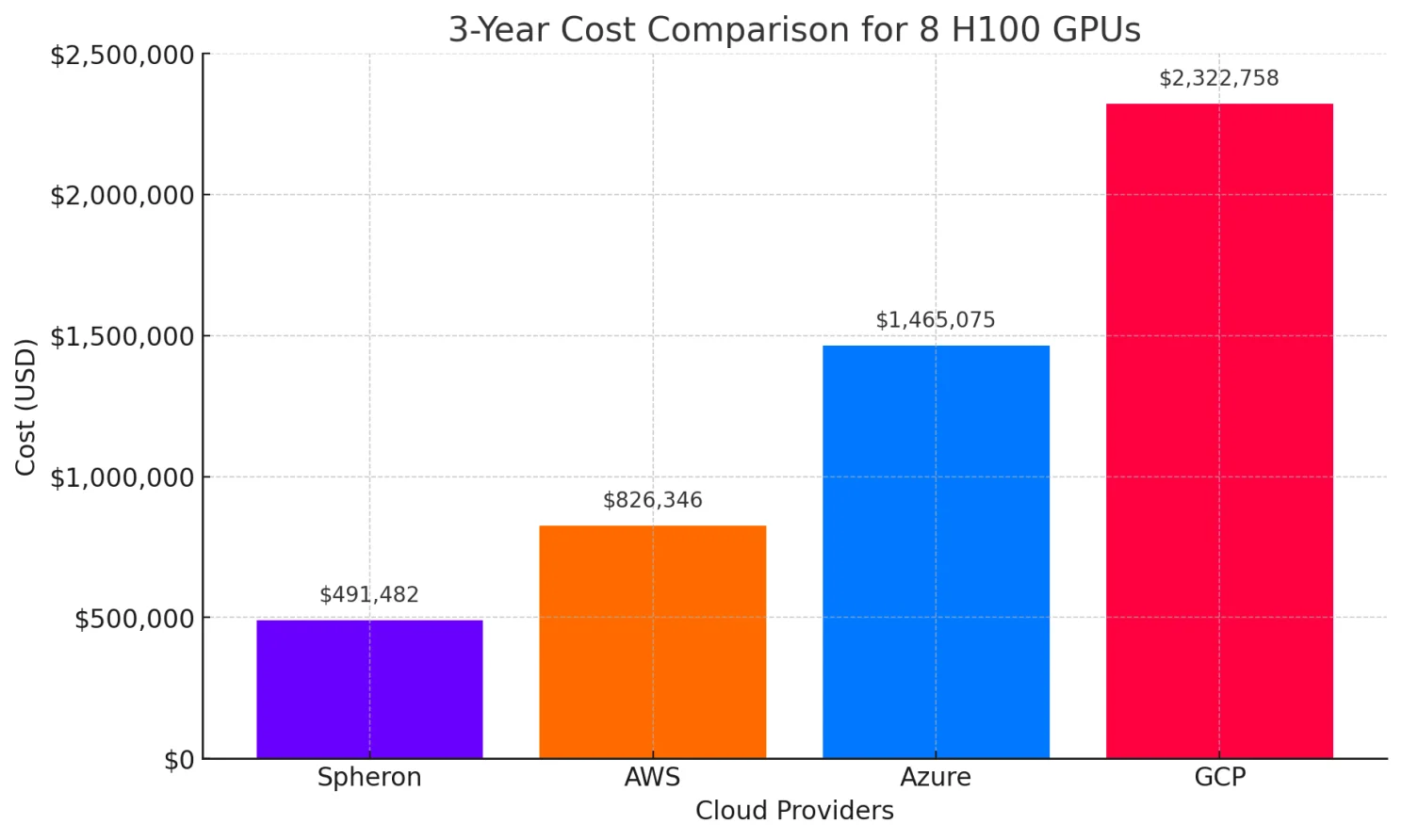
Even conservative cloud usage estimates demonstrate substantial cost advantages. These calculations assume typical AI development patterns with intermittent training runs rather than continuous 24/7 utilization, making them representative of real-world startup and research scenarios.
Optimizing Cloud GPU Expenditures
Strategic approaches to cloud GPU utilization maximize value while minimizing waste, ensuring organizations extract maximum performance per dollar invested.
1. Matching Resources to Requirements
Properly sizing GPU capabilities to specific workload requirements prevents overspending. Not every task demands H100 performance; many workloads execute adequately on mid-tier GPUs at a fractional cost.
Analyzing actual resource utilization reveals optimization opportunities. Models training successfully within 40GB memory waste funds on 80GB GPUs, while insufficient memory allocations cause expensive failures requiring restarts with proper configurations.
2. Strategic Usage Patterns
Tactical timing of GPU utilization maximizes value. Scheduling batch jobs during off-peak hours when some providers offer reduced rates, consolidating workloads to improve utilization density, and promptly releasing resources when jobs complete all reduce total expenditures.
3. Multi-Provider Strategies
Utilizing multiple providers optimizes costs across different workload types. Training on specialized, affordable GPUs while running inference on higher-end GPUs with global distribution balances performance with economics.
This approach requires maintaining workload portability through containerization and standardized APIs. While adding orchestration complexity, potential 40 to 60% cost reductions frequently justify additional management effort.
Performance Characteristics: Cloud Versus On-Premise
Understanding performance implications helps organizations make informed infrastructure decisions based on actual workload requirements rather than assumptions.
1. Hardware Performance Parity
Cloud GPUs deliver identical computational performance to on-premises equivalents: the same silicon and same capabilities. Concerns about cloud performance typically stem from infrastructure factors like networking or storage rather than GPU capabilities themselves.
For single-GPU workloads, cloud and on-premises performance are effectively identical. Multi-GPU training may encounter networking bottlenecks on platforms lacking high-speed interconnects, but leading providers offer NVLink or InfiniBand matching or exceeding typical on-premises configurations.
2. Networking and Bandwidth Considerations
Multi-GPU workloads depend heavily on inter-GPU communication bandwidth. Cloud providers offering NVLink or high-speed InfiniBand deliver performance matching on-premises clusters, while platforms with slower networking may limit scaling efficiency.
Storage I/O similarly impacts certain workloads. Cloud platforms with high-speed NVMe storage systems prevent data loading from becoming bottlenecks, maintaining GPU utilization throughout training runs.
3. Latency and Geographic Distribution
Geographic distribution of cloud resources enables low-latency access globally. Organizations can deploy inference closer to end users than most on-premises configurations allow, actually improving performance compared to centralized self-hosted infrastructure.
Availability guarantees from reputable cloud providers frequently exceed what small organizations achieve with on-premises hardware. Redundant infrastructure, professional operations teams, and geographic distribution combine delivering exceptional uptime.
4. Real-Time Inference Requirements
GPU-accelerated inference proves ideal for real-time applications requiring low latency and high throughput. Cloud GPU platforms support applications like computer vision, natural language processing, autonomous vehicles, and recommendation systems demanding rapid response times.
Optimization techniques including batching strategies (continuous batching typically delivers 10-20x better throughput than dynamic batching), quantization reducing model precision from 32-bit to 8-bit or 4-bit, and specialized inference servers like NVIDIA Triton or vLLM significantly enhance inference performance on cloud infrastructure. To learn more about GPU selection for LLMs, see our guide on the best NVIDIA GPUs for LLMs.
When On-Premise Infrastructure Might Make Sense
While cloud GPU rentals deliver superior economics and flexibility for most scenarios, specific circumstances may justify an on-premises investment.
Organizations with genuine 24/7 GPU utilization sustained over 2-3 years might achieve lower costs with owned hardware. However, rapid improvements in GPU architecture frequently render hardware obsolete before it reaches break-even, undermining long-term economic advantages.
1. Data Sovereignty and Regulatory Requirements
Certain industries face regulatory requirements demanding on-premises processing of sensitive data. Financial services, healthcare, and government organizations frequently navigate data sovereignty constraints restricting where data physically resides and how it traverses borders.
Even in these scenarios, hybrid approaches often work, maintaining sensitive data on-premises while leveraging cloud GPUs for non-sensitive workloads. This balanced strategy preserves regulatory compliance while accessing cloud economic advantages.
Regulations like GDPR in Europe, PIPL in China, and PDPB in India impose varying degrees of data localization requirements, with some mandating specific data types remain within national borders while others focus on transfer controls and adequate protection standards.
2. Specialized Custom Requirements
Organizations requiring extensive hardware customization or running highly specialized workloads may benefit from on-premises infrastructure offering complete control over configurations. However, cloud platforms increasingly support customization through bare-metal offerings, BYOC (bring your own cloud) deployments, and flexible instance configurations.
3. Scaling Production Organizations
Organizations transitioning from experimentation to production benefit tremendously from cloud elasticity. As needs grow from occasional experiments to continuous production workloads, cloud platforms scale seamlessly without hardware procurement delays or infrastructure expansion projects.
Specialized GPU cloud providers offer particularly attractive economics for scaling organizations. Platforms like Spheron deliver A100 GPUs at $0.66/hour, and support powerful options like the H100 for demanding workloads.
Making Infrastructure Decisions: A Practical Framework
Organizations should approach GPU infrastructure decisions methodically, considering financial, operational, and strategic factors comprehensively.
1. Financial Analysis
Calculate total ownership costs, including hardware acquisition, facility infrastructure, power and cooling, networking equipment, maintenance, and opportunity costs of engineering time spent on infrastructure rather than product development. Compare against cloud costs for equivalent workloads, carefully factoring in usage variability and growth projections.
Organizations should model multiple scenarios reflecting realistic usage patterns rather than theoretical maximums, as actual utilization frequently runs substantially below initial estimates.
2. Flexibility and Technology Risk
Cloud rentals eliminate the technology risk associated with rapid GPU architecture evolution. New GPU generations emerge regularly; cloud users simply switch instance types, while hardware owners face expensive upgrade cycles and asset depreciation.
Business uncertainty similarly favors cloud approaches. Startups facing uncertain computational needs benefit from aligning expenses with actual requirements rather than committing capital to infrastructure that potentially exceeds needs or constrains growth.
3. Operational Considerations
Evaluate organizational capabilities honestly. Does the organization possess expertise in managing GPU infrastructure? Are personnel resources available for ongoing maintenance? Would engineering focus on infrastructure detract from core product development?
For most organizations, cloud platforms deliver superior operational efficiency by shifting infrastructure complexity to specialized providers, while internal teams focus on differentiated capabilities.
4. Strategic Recommendations
For the overwhelming majority of developers, researchers, and startups, cloud GPU rentals deliver superior economics, flexibility, and operational simplicity. Specialized platforms offering affordable but powerful GPU access eliminate cost barriers while providing performance matching owned hardware.
Organizations should start with cloud infrastructure, carefully tracking usage patterns and costs over time. Only after establishing consistent high-volume needs sustained over extended periods does on-premises investment potentially make financial sense, and even then, hybrid approaches frequently optimize better than pure on-premises deployments.
The Shifting Economics of AI Infrastructure
The economics of GPU infrastructure have decisively shifted toward cloud rentals across most use cases. Access to powerful GPU resources at competitive prices through specialized platforms eliminates capital requirements, operational complexity, and technology risk inherent in ownership.
Cloud GPU rentals typically cost 50-70% less than on-premises infrastructure over three-year periods when accounting for total ownership costs, including hardware, operations, facilities, and opportunity costs. Platforms like Spheron deliver enterprise-grade hardware at startup-friendly prices, with H100 instances available from $2.05/hour and A100s as low as $1.53/hour compared to hyperscaler pricing often exceeding $3-7/hour.
The combination of instant provisioning, pay-as-you-go economics that align costs with actual usage, eliminated infrastructure overhead freeing engineering resources for product development, continuous access to the latest GPU generations without upgrade cycles, and global distribution enabling low-latency inference makes cloud GPU rentals the logical choice for modern AI development.
On-premises ownership increasingly represents the exception, justified primarily by specific regulatory requirements mandating data localization or truly exceptional usage patterns with genuine 24/7 utilization sustained over multiple years. Even in these scenarios, hybrid approaches combining on-premises infrastructure for compliance-sensitive workloads with cloud resources for flexible capacity often deliver optimal outcomes.
As AI development accelerates and GPU technology continues to evolve rapidly, the advantages of cloud flexibility over ownership will strengthen further. Organizations embracing cloud GPU infrastructure position themselves to compete effectively while preserving capital for innovation rather than depreciating hardware assets. The democratization of powerful GPU access through affordable cloud platforms has fundamentally transformed AI development from an enterprise-exclusive pursuit into an achievable goal for teams of any size.
Ready to cut your AI training costs in half? Get started with Spheron and experience enterprise-grade GPU infrastructure at startup-friendly prices. View our pricing page to see current rates, or dive deeper with our comprehensive top GPU rental options guide.